This week we run the Interdisciplinary Summerschool on Privacy in Berg en Dal, the Netherlands. Here is a summary of the talks of Tuesday June 20.
Bibi van den Berg
Bibi studies questions of regulations, i.e. how to ensure that new technologies don't infringe on fundamental rights, like privacy. Bibi is not a lawyer (she is a philosopher instead), but she has worked at several law schools. And she has concerns, e.g about the extent of the protection offered by the General Data Protection Regulation (GDPR).
Concerns
Data Analytics: Personal data is the cornerstone of GDPR. Yet vast amounts of data collected and analysed is not personal data, or could at least be contested to be personal data, so how does GDPR protect us? Bibi is in particular worried that in practice there will be endless debates about what is personal data. E.g. is inferred, aggregated, data also personal data? Is data collected in a home (but not attributable to a single natural person) also personal data? Moreover, the correlations deduced from such non-personal-data streams may, when combined with small pieces of personal data of yourself, reveal or predict some very sensitive data about you (e.g. when the data analytics show that there is a 95% correlation between certain personal traits and living in a certain area and catching a particular kind of deadly cancer).
Internet of Things: Consumers love fridges that can connect to the Internet and order supplies that are running low, coffeemakers that you can connect to the Internet, or bikes that you can connect to the Internet to log the bike trips you made. These devices collect vast amount of data, generating the data trails Bibi is worried about.
Cybersecurity: IoT devices currently are very insecure. They are equipped with sensors and actuators, and used in very private spaces, so their insecurity leads to privacy concerns. For example, they are used by 'special', vulnerable, user groups, like children (smart toys), or elderly people (smart care). Additionally, we have seen insecure IoT devices being used as part of massive botnets.
Security vs safety
Bibi discussed the distinction between threats (that are intentional, security perspective) vs dangers (that are non-intentional, safety perspective). They are studied by different scientific domains. But privacy specialists don't make this clear distinction! (E.g. losing a USB stick with personal data is strictly speaking a safety incident, not a security incident; the same could be said of people oversharing on Facebook).
A huge discussion with the audience ensued. It was noted that different discourses, e.g politicians and policy people, view the distinction as very small. They will, for example, frame national security as something that keeps people safe. Others even questioned whether the distinction is even relevant. And then there were people pointing out that safety focuses more on resilience, on what happens after the incident (i.e. how to recover) while security focuses on prevention. The distinction also relates to the amount of agency people perceive, and whether others can be blamed or held liable. For example, someone remarked that framing criminality as a public health issues totally changes the perspective... Bibi closed the discussion remarking that cybersafety is underdiscussed.
Cybersafety
According to her Cybersafety (and to be honest the difference with cybersecurity is not entirely clear to me) is hard to achieve. People have all sort of interests that override their security and privacy concerns. Companies put insecure products on the market because making more secure ones cost money, innovation/business cycles are short, and the competition is killing. Fitting products with an internet connection allows collection of all kinds of data, but also allows remote updates (with security features) in theory (although that rarely happens in practice, at least for smaller, cheaper, devices). One approach could be to introduce stronger liabilities for producers?
A broader view on regulation
Law is slow to catch up with technological developments. Bit in fact this is a good thing because law should be stable and predictable. Lawyers focus only on law. They only see law as possible to remedy 'wrongs' in society. But there are other approaches, for example social norms steer to a large extent how we behave and interact, market forces (e.g. pricing mechanisms) influence what we do and do not do. Similarly architecture shapes how we interact: you don't enter the building through the window, but through the door. The same holds for IT architectures and the Internet: the way services are designed shapes what you can and cannot do. This is all brilliantly explained in Lawrence Lessig's book Code and other laws in cyberspace, highly recommended by Bibi (and I agree!). He specifically targets designers to make them aware that they are writing law. Hence the phrase "code is law". Unfortunately there still is very little debate, interaction, between the traditional law makers and the new 'law makers' from Silicon Valley.
How does this relate to the Internet of Things?
The Internet of Things is presented to us as something unavoidable, as the final stage of ambient intelligence, pervasive computing and ubiquitous computing. It is not discussed or challenged by society; the development is all left to the market, that fits Internet connections to all devices they produce
Privacy by design makes clear, for the first time, that they are choices in the way we design technology (not only for technology). (I guess one could argue that in that sense privacy by design is a logical consequence of Lessig's code is law principle.)
Consumers should be aware that they don't need to be an internet connected toothbrush. This is more urgent than ever as risks increase with technological developments. Bibi wants to criticise that this wave is inevitable. At the least we want consumers to be well informed in the choices they make.
But creating awareness is hard. Information campaigns are only effective if you keep doing it for 25 years and if you have a really simple message, e.g. the 'don't drink and drive' campaign is very effective. Information technology is often hard to visualise (because of the 'virtualness' of the problem) and the problem space is too complicated to dumb it down. Education (e.g. should children learn how to code?) only targets those that are in school and hence take a long time to have a significant effect.
Bibi suggested a third approach involving local governments. In a new project in Rotterdam and The Hague neighbourhood teams that already advice locals on burglary prevention or fire prevention, also advice on cybersecurity risks (and help fix problems like setting a proper WiFi password). So this goes beyond awareness to actively helping citizens, intervening in their home situation. This is quite a paternalistic approach for which you have to trust your local government. Also, this uses public money to solve problems created by private companies. (See also Bejamin Barber's If Mayors Ruled The World.)
Bibi also mentioned the CE standard for electrical appliances and suggested we should have something similar for Internet of Things: a minimum set of standards that all devices have to conform to. It's not either-or: you have to both increase awareness and reverse "Reponsibilisation" (where companies want to move responsibility squarely to the user).
In the discussion with the audience the issue of metaphors and affordances (how the visual/physical design defines what you think you can and cannot do with an object) came up. Designers make choices about what we can and cannot do with their designs. Then the question is who is responsible for designing the right metaphors, as these have a strong impact on how users perceive e.g. risks and hence influence awareness. Yet laws don't regulate perception...
Conclusion
Bibi challenges the inevitability of the Internet of Things, and proposes air gaps to disconnect IoT devices from the full internet. Instead they should only be connected to the home network. This solves quite some problems, yet this still leaves privacy issues within the house environment, like children wanting to be 'disconnected' from their parents. And it reduces utility: it is no longer possible to adjust the thermostat while travelling home, and the fridge can no longer order supplies that are short.
(Someone lamented the fact that the physical switch on laptops to turn off WiFi has gone...)
Hadi Asghari
Hadi talked about the economical aspects. He challenged whether privacy laws matter (little, given current business models and the fact that billion dollar industries have to be controlled by data protection offices with a staff of 20 people in Ireland), and whether privacy enhancing technologies have real-life impact (little, given that a very small fraction of the Internet users is using Tor, Signal, DuckDuckGo; with the exception of the Whatsapp user-base, which is large). Yet people care about privacy. E.g. Pew studies show that 60% US citizens really care strongly about privacy. The rise of ad blockers is a sign of this too, and there is a lot of press coverage. Also, every year students are more concerned about privacy.
Privacy economics
Privacy economics (as a branch of information economics) can explain the situation, studying the trade-offs (not only monetary), the incentives and actions of data subjects and data holders regarding personal information
The core concept is information goods: the first copy can be costly, but next copies (the marginal cost) is essentially zero. This leads to certain pricing strategies.
Then there is attention scarcity: "A wealth of information creates a poverty of attention (Herbert Simon). So the amount of time a company can grab your attention determines its value. This is one of the reasons that Facebook does not offer the option to get a daily report of everything that happened on your network. Instead, they want to get you to check Facebook every few minutes.
Two-sided platforms that have to cater for two different user groups, where the value of the platform for one group is dependent on a reasonable number of participants of the other group. This creates a lot of lock-in effects, and hence a monopoly (Hadi called it centralisation, but this not necessarily means a centralised architecture, but more conceptually like a virtual central service - like Facebook as 'the' social network)). This is similar to the consequences of the network effect, where the value of a product or service increases as more people are using it. Intermediaries offering such platforms experience non-linear growth.
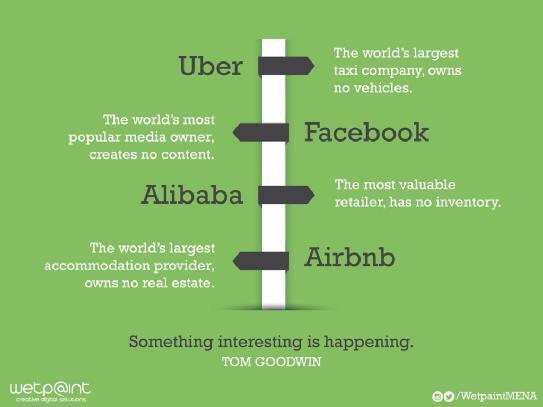
There is a pernicious cycle where capital enables the use of Big Data with which you can grab attention and nudge people which leads to (political) power which creates more capital.
Business models matter. E.g. Apple making money by selling expensive hardware makes that they can differentiate themselves as being more privacy friendly: they do not need our personal data to make a profit (unlike Google or Facebook).
Research strategies
Earlier empirical studies focused on users, e.g the impact of identification, privacy preference measurements, monetisation of privacy. Currently the focus is on organisations, looking at e.g. data breach notifications, and web transparency.
Data breach notification laws have made the general public more aware of the extent and severity of the issue. Companies especially care about user perception, not the associated fine.
Web transparency research, e.g the work by Latanya Sweeney that showed that when searching for names that appear to refer to people of colour on Google, Google would show advertisements for "has X been arrested?". Or the research by Gunes Acar, Claudia Diaz and others on persistent tracking mechanisms on the web to counter and keep on tracking people clearing their cookies. There is a new trend of large scale empirical studies to investigate these practices further, which sometimes leads to exposed techniques being withdrawn from use.
A study of EU-cookie law effects looked at the effect of different local interpretations of consent (explicit vs. implicit); it showed that websites in countries that have a strict interpretation indeed drop fewer cookies.
Aligning incentives
To align incentives one could define (and enforce) regulation, taxes, subsidies, reputation metrics. Also, transparency may lead to collective demand.
EU Open Technology Foundation (OTF) could be a way to fund alternatives, say public infrastructures. Research funding like H2020 is less suitable, as it is quite bureaucratic and it isn't very easy to change the approach fundamentally midway a project if you discovered the approach will not deliver the best possible result. Projects like Tor have a few million dollar to spend yearly.
Metrics and seals must measure real privacy and deal with perverse incentives (like especially dodgy companies willing to pay for a seal to 'whitewash' their image).
But perhaps there are other governance models. Hadi proposed a 'data board' (making decisions about data processsing) different from the board of directors, with representatives from their users and the company itself, as a way to reinstate the 'trias politica' in a domain where companies provide public services harvesting public data. It would balance trade-offs and ensure benefits are fairly shared. Is there a role for an external supervisory body, similar to data protection authorities? The audience noted that an extreme example of governance of platforms is offered by China ;-) And it was believed highly unlikely that the US legislator is going to allow other countries to determine what happens in US companies.