Privacy by design requires that privacy concerns are tackled throughout the full life cycle of system development. In this paradigm, privacy protection is a system requirement like any other functional requirement, that must be addressed from the beginning, and that shapes the final design and implementation of the system. To support privacy by design, we therefore need guiding principles to resolve privacy requirements throughout the system development life cycle, in particular during concept development, analysis, design and implementation phases. To this end, this blog post (and the accompanying full paper) presents eight privacy design strategies.
Strategies, patterns and technologies
Privacy issues can be resolved at several levels of abstractions. At the lowest level, privacy enhancing technologies implement specific privacy protection mechanisms. These technologies are important during the implementation phase. Design patterns are tools at a higher level of abstraction that "describe a commonly recurring structure of communicating components that solves a general design problem within a particular context". They apply to the design phase and do not necessarily play a role in the earlier, concept development and analysis, phases of the software development cycle. The main reason is that such design patterns are already quite detailed in nature, and more geared towards solving an implementation problem. To guide the development team in the earlier stages, privacy design strategies at a higher level of abstraction are needed.
Privacy design patterns can be mapped to privacy design strategies. This mapping is not unique: a pattern may implement more than one strategy. Similarly, privacy enhancing technologies implement one or more design patterns. By studying these mappings (of which the current research is just a first step) we can identify for which strategies adequate patterns are missing, and similarly, for which patterns new technologies need to be developed.
Deriving privacy design strategies
A natural starting point to derive some privacy preserving strategies is to look at when and how privacy is violated, and then consider how these violations can be prevented. I have taken Daniel Solove's taxonomy [Solove, D.J. A taxonomy of privacy. University of Pennsylvania Law Review 154, 3 (2006), 477-564] as point of departure here. His general subdivision of activities that affect privacy (information collection, information processing, information dissemination and invasions) inspired us to look at IT systems at a higher level of abstraction to determine where and how privacy violations can be prevented.
Current data protection legislation in general views an IT system as an information storage system, i.e. a database system where personal identifiable information about people is stored in one or more database tables. Applying this legislation to such systems, the following general observations can be made. Data collection should be minimised, for example by not storing individual rows in a database table for each and every individual, and the number of attributes stored should correspond to the purpose. Data collected for one purpose should be stored separately from data stored for another purpose, and linking of these database tables should not be easy. When data about individuals is not necessary for the purpose, only aggregate data should be stored. Personal data should be properly protected, and strict access control procedures should limit access to authorised persons only. A data subject should be informed about the fact that data about her is being processed, and she should be able to request modifications and corrections where appropriate. In fact the underlying principle of information self-determination dictates the she should be in control. Finally, the collection and processing of personal data should be done in accordance to a privacy policy, that should be actively enforced. The current proposal for the revision of the European privacy directive (into a regulation) also stresses the fact that data controllers should be able to demonstrate compliance with data protection legislation.
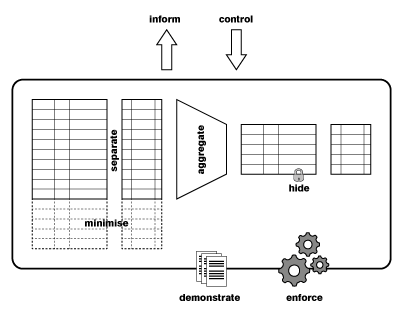
Given this analysis form the legal point of view, we see we can distinguish the following eight privacy design strategies: minimise, separate, aggregate, hide, inform, control, enforce and demonstrate. A graphical representation of these strategies, when applied to a database system, is given in this figure. In the full paper I also show that these strategies cover the privacy principles of the ISO 29100 Privacy framework, and I verify that the strategies can also be easily understood in the context of information flow systems.
The eight privacy design strategies
Strategy #1: Minimise
The amount of personal information that is processed should be minimal.
By ensuring that no, or no unnecessary, data is collected, the possible privacy impact of a system is limited. Data minimisation can take two forms: either a yes/no decision to collect any information about individuals is made (as a consequence, for some people no information will be collected at all), or the amount of information that is collected about each person is restricted to a limited set of characteristics. A common design pattern is select before you collect, anonymisation, and the use of pseudonyms.
Strategy #2: Hide
Any personal information that is processed should be hidden from plain view.
The rationale behind this strategy is that by hiding personal information from plain view, it cannot easily be abused. The strategy does not directly say from whom the data should be hidden. And this depends on the specific context in which this strategy is applied. In certain cases, where the strategy is used to hide information that spontaneously emerges from the use of a system (for example communication patterns), the intent is to hide the information from anybody. In other cases, where information is collected, stored or processed legitimately by one party, the intent is to hide the information from any other, third, party. In this case, the strategy corresponds to ensuring confidentiality.
Common design patterns are the use of encryption (locally, or on the network using SSL), the use of onion routing to hide traffic patterns or anonymous credentials.
Strategy #3: Separate
The processing of personal information should be done in a distributed fashion whenever possible.
By separating the processing or storage of several sources of personal information that belong to the same person, complete profiles of one person cannot be made. The strategy of separation calls for distributed processing instead of centralised solutions. In particular, data from separate sources should be stored in separate databases, and these databases should not be linked if not needed. Data should be processed locally whenever possible, and stored locally if feasible as well. Database tables should be split when possible (and links between rows should be hard to find).
These days, with an emphasis on centralised, web based, services, this strategy is often disregarded. Further investigations into design pattern that implement the separate strategy are required, especially those that will satisfy business needs that usually steer towards a centralised solution.
Strategy #4: Aggregate
Personal information should be processed at the highest level of aggregation and with the least possible detail in which it is (still) useful.
By restricting the amount of detail of personal information, or by considering this information at the group level instead of considering this information for each person separately, this personal information becomes less sensitive. When the information is sufficiently coarse grained, and the size of the group over which it is aggregated is sufficiently large, little information can be attributed to a single person, thus protecting its privacy.
Common design patterns are aggregation over time (for example used to provide some level of privacy protection in smart metering and smart grid systems), dynamic location granularity (used in location based services where the accuracy of the reported location of a user is adapted dynamically to ensure that a reasonable number of other users are at the same location).
Strategy #5: Inform
Data subjects should be adequately informed whenever personal information is processed.
Often, data protection regulation requires that data subjects are properly informed about the fact that personal information is processed when they use a certain system (or when they enter an area with camera surveillance). The inform pattern underlines this fact. Data subjects should be informed about which information is processed, for what purpose, and by which means. This also includes information about the ways the information is protected, i.e. being open about the security of the system (the Kerckhoffs Strategy). Data subjects should also be informed about third parties with which information is shared.
Possible design patterns in this category are transparency, the (these days pretty much defunct) Platform for Privacy Preferences (P3P) and data breach notifications.
Strategy #6: Control
Data subjects should have agency over the processing of their personal information.
The control strategy is in fact an important counterpart to the inform strategy. Without reasonable means of controlling the use of ones personal information, there is little use in informing a data subject about the fact that personal information is collected. Data protection legislation often gives the data subject the right to view, update and even ask the deletion of personal data collected about him. This strategy underlines this fact, and design patterns in this class will give users the tools to exert their data protection rights.
Control goes beyond the strict implementation of data protection rights, however. It also governs the means by which users can decide whether to use a certain system, and the way they control what kind of information is processed about them. In the context of social networks, for example, the ease with which the user can update his privacy settings through the user interface determines the level of control to a large extent. So user interaction design is an important factor as well.
I am not aware of specific design patterns that fit this strategy, although informed consent, and certain user interaction design patterns could fit the bill.
Strategy #7: Enforce
A privacy policy compatible with legal requirements should be in place and should be enforced.
The enforce strategy ensures that the system is compatible with data protection legislation, both at the time when the system is developed, as well as when the system is in operation. By specifying a privacy policy, and setting up the appropriate governance structures to enforce that policy, proper embedding of the IT system within the organisation is established.
Design patterns that implement this strategy could be certain types of access control, and systems that implement privacy rights management (a form of digital rights management involving licenses to personal data, but then applied to privacy).
Strategy #8: Demonstrate
Demonstrate compliance with the privacy policy and any applicable legal requirements.
This strategy goes one step further than the enforce strategy in that it requires the data controller to prove that it is in control. In particular this requires the data controller to be able to show how the privacy policy is effectively implemented within the IT system. In case of complaints or problems, he should immediately be able to determine the extent of any possible privacy breaches, for example.
Design patterns that implement this strategy are, for example, privacy management systems, and the use of logging and auditing.
Concluding remarks
I have presented eight privacy design strategies, described them informally, and (where possible) indicated which privacy design patterns contribute to these strategies. A more precise description of these principles is under development, including more elaborate descriptions that help to apply these strategies in practice. Your feedback is more than welcome on these points.
I am not terribly happy with the name of the eight strategy demonstrate...
In general I see that a large collection of privacy enhancing technologies exists, and that there is a quite active research community in this area. This is not the case for privacy design patterns. I have been unable to find more than a handful, and event those that I found are described in varying levels of detail and differ widely in scope. In this research I have hinted at several other design patterns (e.g. transparency, data breach notifications) that are not described in any detail yet. This is ongoing work. Progress can be found (and your contributions are welcome!) at this privacy wiki.
[…] http://www.cs.ru.nl/~jhh/publications/pdp.pdf http://blog.xot.nl/2012/09/10/eight-privacy-design-strategies/ […]